CosMo
For Interleaved Vision-language Pre-training
Alex Jinpeng Wang
Linjie Li
Kevin Qinhong Lin
Jianfeng Wang
Kevin Lin
Zhengyuan Yang
Lijuan Wang
Mike Zheng Shou



Please scroll down to continue
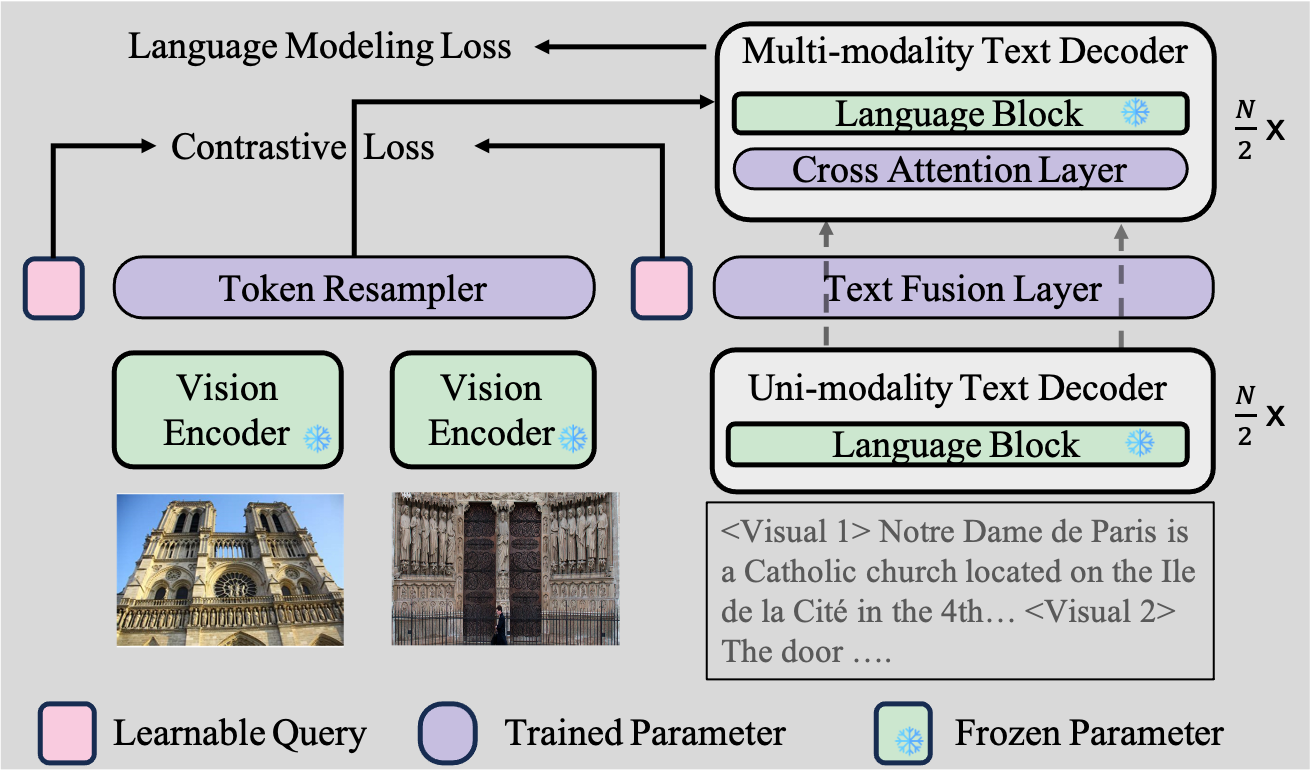
In the evolution of Vision-Language Pre-training, shifting from short-text comprehension to encompassing extended textual contexts is pivotal. We introduce the contrastive loss into text generation models, presenting the COntrastive-Streamlined MultimOdal framework (CosMo), strategically partitioning the language model into dedicated unimodal text processing and adept multimodal data handling components.






Howto-Interlink7M Dataset Download.
Download data directly from Huggingface ListView. .HowTo100M source video download.
The source video can be found here.Dataset Statics.
More details about dataset statics can be found at here.







Model Card
| Method | Language Model | Vision Model | Samples | Model Weight |
| CosMo2.1B | OPT-IML1.8B | 130M | VIT-L | Pretrained Weight |
| CosMo3.4B | RedPajama-3B | 180M | VIT-L | Pretrained Weight |
| CosMo8.1B | Mistral7B | 180M | VIT-L | Pretrained Weight |
Model Explorison
Our codebase also support training following models on A100 GPUS:| Language Model | Size | Batch Size | GPU Memory |
| Vicuna | 7B | 196 | 70G |
| LLaMA | 7B | 196 | 70G |
| Mixtral7x8b | 42B | 32 | 80G |
Acknowledgement
This work is mainly based on:
-MMC4
Others
We thanks:
-Ziteng Gao for discussing the training stability of Multi-Node.
-Henry Zhao for his insights on the design of the lightweight cross-attention model.
⇧